In the first part of this two-part series I discussed the use of MindManager as a research tool and specifically the benefits provided by the addition of reusable text tags in analysing interview and survey data. I also provided two approaches to copying text tags. In Part 2 I’ll outline some data entry techniques and research approaches. I’ll also examine some of the limitations involved in using tags and MindManager more broadly as a research tool.
Data entry options
I could write an entire post – indeed a series of posts – just on data entry, but I’ll try to condense my comments.
In the previous post I described my preferred methodology, which relies on creating a mind map in developing the survey or interview process and writing the individual questions. The responses can then be integrated directly into the map, moving from question to question and if necessary moving around to different parts of the map if respondents provide answers to a question which contain material relevant to other questions.
Even if you were unable to develop a map prior to the conduct of the survey or interview process the resulting material can still be turned into a usable map. The situation is relatively straight-forward if the material was recorded question-by-question, for example tabulated responses from a survey or questionnaire, as you should be able to import this directly into a map from Word or Excel with main topics representing the questions (see this article for additional tips on importing from standard Word documents and this one for importing from tables). If you use this approach then you will probably need to add a text tag to identify each respondent after importing the answers.
If the answers were recorded on a per-respondent basis (for example, as interview transcripts) the situation is more complex. Provided the transcripts are in Word format (or can be converted to it) you can still import them, but you will end up with the respondent names as the main topics. While it is possible to run the tagging and analysis process I described in Part 1 with the material organised this way you the duplicate tag groups could easily cause confusion. Besides, one of the benefits of organising the material on a question rather respondent basis is that it is much easier to build a picture of the range of answers relating to each question at a glance.
You can however use tags to create a question-based map from one based on respondents using the following process:
- Import the survey responses or interview transcripts for each respondent into a new map. There should be a main topic for each respondent and each answer should be represented by a sub-topic.
- Create a tag group in the Map Index of the map with a unique tag for each respondent name/code, then apply the relevant tag to all the sub-topics containing each respondent’s answers.
- In the General Tag group create a unique tag for each question, for example, Q01, Q02, Q03, etc., and apply the relevant tag to all the sub-topics containing the respondents’ answers. This means that each answer sub-topic in the map should have a respondent’s name tag and a Question tag.
- Create a new map in which the main topics are the survey/interview questions.
- Return to the original respondents map and copy the respondent tag group in the Map Index, then switch to the new question-based map and paste the tag group in the new Map Index.
- Return to the original respondents map and use the power filter to select all the answers with the tag for the first question. Copy these answers, switch to the new question-based map and paste them as sub-topics under the first question main topic.
- Repeat step 6 for each question. When you are finished check that all the answers have been pasted under the correct questions and that the total counts for the question code and respondent tags match between the maps. You may find that answers are not pasted within each topic with same order you established for the respondent tags but this shouldn’t matter too much as long as the respondent tags are retained.
- In the new map create separate answer tag groups for each question with the different categories, rankings, comment etc. for the answers to each question each represented by a tag (also see comments below under Research Approaches). To create identical duplicated tag sets across a number of questions follow the process outlined in Part 1.
- Review the answers and if necessary break up the answer-sub-topics into smaller sub-topics, then apply the answer tags to each of these sub-topics. If you do break up the answers don’t forget to add the relevant respondents tag as well to each of the new sub-topics.
- Once the answers have been processed and the appropriate respondents and answer tags applied you have the option to either retain or remove the question code tags. If you decide to retain them then don’t forget to apply these as well to any new answer sub-topics.
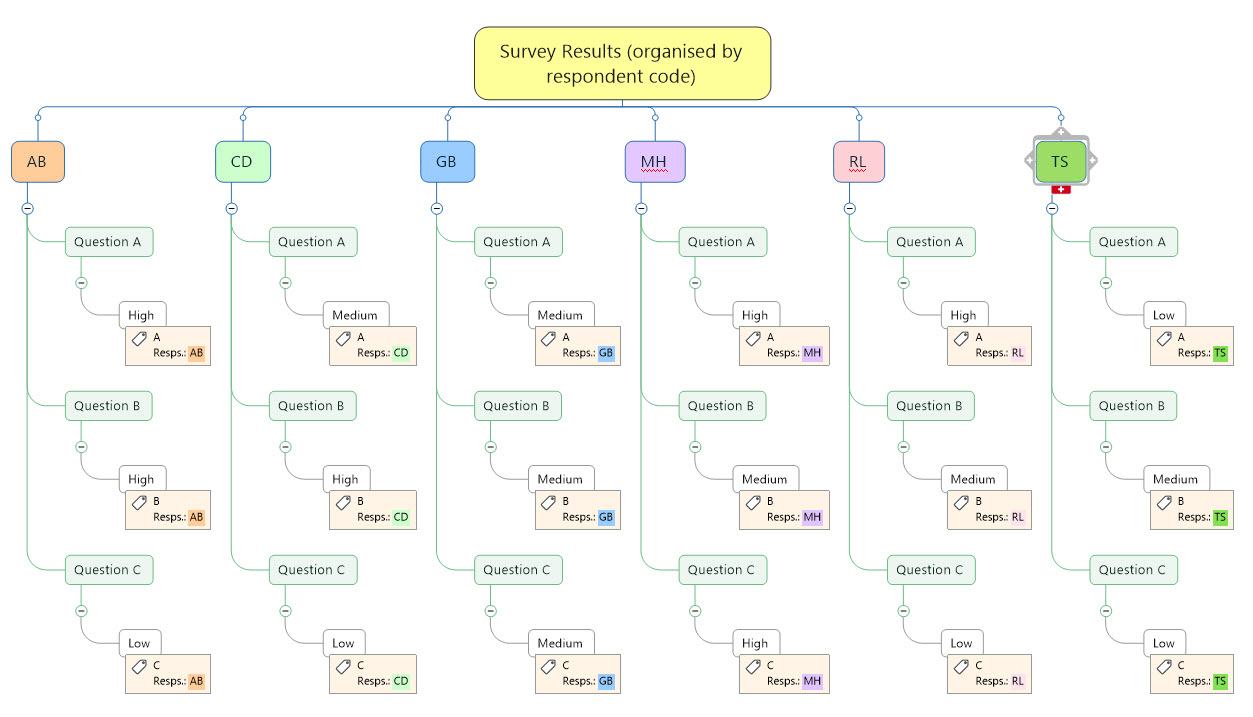
Survey results hypothetical example organised by respondent name code

Map Index for the above map showing question tags (in the General Tags group) and the respondents (Resps) name code tag group

Survey results example organised by questions
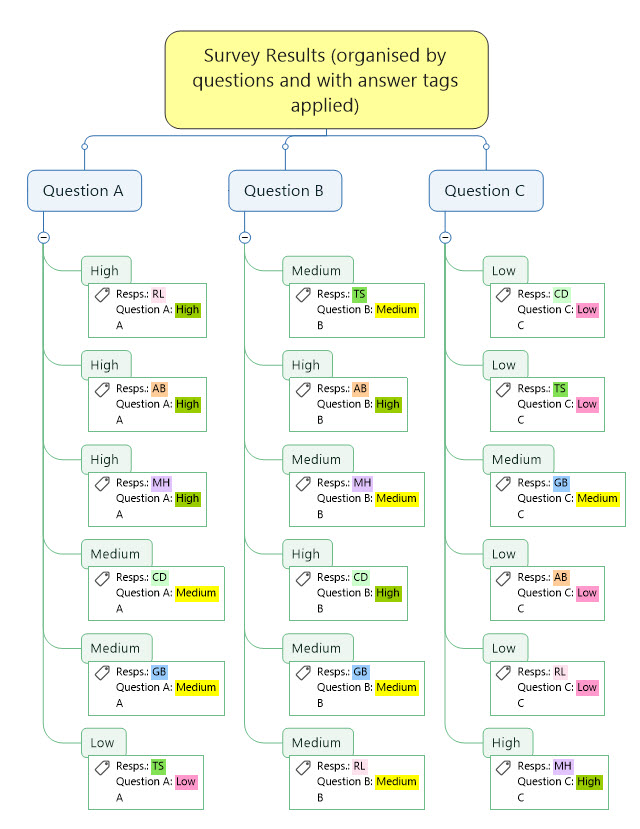
Survey results example organised into questions with answer category/code tags applied

Map Index for the above map incorporating the answer tags
At the end of this process you should have a map with the respondent transcripts reorganised on a question-by-question basis but with each answer sub-topic being coded with a single tag identifying the respondent, one or more answer category tags and, optionally, a single question code tag. While it would be ideal to be able to apply the answer code tags in the original respondents map before importing the contents in to a new question-based map, there appears to be a bug which affects the copying and pasting of duplicated tag groups into new maps. That’s why I suggest creating and applying any the category/ranking/ comment tag sets in the new map after the import process is completed, especially if any of these sets involves the use of duplicated tags.
Research Approaches
There are any number of possible schema for creating category tag groups and the approach you choose will reflect the nature of your research and its outcomes. Broadly speaking however there are two ways to use tags in analysing your material; quantitative and qualitative.
Quantitative…
The marker index topic count provides an easy way to interpret numerical data, for example the number of answers to a specific question that supported or opposed a particular proposition, or the number that ranked an issue as being of high, medium or low priority.
Obviously you have to be careful in using these results, especially if you are tagging based on your interpretations of complex answers rather than using tags simply to count the responses to multiple-choice questions (though if you are mainly doing the latter a spreadsheet rather than a mind map may be a more appropriate tool). You also need to decide (especially for multiple-choice questions) if more than one answer is permitted or if the responses – and the tags – will be mutually exclusive. The latter is more appropriate if you are going to look at proportions of the total number of responses for each question.
While I have mostly described situations in which you are setting up a single tag group for each question or interview topic, there is nothing to prevent you having more than one group for question (or in some cases a tag group that spans more than one question). You can also use the power filter to highlight correlations and differences between the responses to one or more questions and other characteristics, for example, geographic location, age, gender, position or type of organisation.
There is one frustrating limitation – while the Marker Index shows the topic count for each tag (assuming this option has been ticked in the Marker Index View menu), these numbers have to be transcribed by hand. While the Marker Index can be copied and pasted in a document or spreadsheet outside MM, the topic counts are lost in this process.
Qualitative….
This I think is where the MindManager advantage really shines. Tagging provides a great way to categorise longer survey responses and in doing so to draw out finer details which might otherwise be lost. To assist in this process, text tags can be made a bit longer than qualitative tags. In most cases they are likely to be developed through the iterative process I described in Part 1, though this does not prevent their reuse across similar questions. The following example tag group is based loosely on a project I was involved in examining coordination and integration options for community services provided by local government:

Example of a qualitative tag group
These tags can be used to explore broad trends – for example, it would be interesting if all the respondents in rural areas identified one group of benefits while city-based ones selected another. The main benefit however is the ability when you are writing up the research to use a tag group like this either by itself or in conjunction with the power filter to group the components of the responses relating to specific benefits. This process of filtering and grouping can help develop new insights regarding the survey material.
Somewhat perversely, undertaking qualitative analysis like this is somewhat easier than quantitative research with MM. While topic counts for each tag can’t be copied from the Marker Index, the tags and topics themselves – or at least the first lines of each topic – can. In addition, the filtered topics will appear in full in the map and can also be copied from there either into another map or an external document.
… and both
Another advantage of MM is that it can bring together quantitative and qualitative research in a visual and practical way. The Marker Index shows both the topic count for each tag and the topics themselves, along with the full topics in the map when it is filtered. This makes it easy to first identify the areas where there is a high degree of consensus or dissent and then explore the relevant responses. You can also use the topic count in a similar way to examine the responses based on variations in the characteristics of the survey respondents.
Tagging in colour
While using coloured tags is not essential, it can assist in making large maps a little easier to navigate. You might decide to establish a consistent set of colours for the same tags if you are reusing tag sets across several questions. Conversely, you could consider using a single distinct colour for each tag group; this can be helpful if you have created a special tag set which can used across a number of questions. This approach also makes it easier to distinguish at a glance which tag group a common topic, for example, “Medium”, might belong to.
If you do want to add colour to your tags, don’t forget that if you are using the MAP feature to convert sub-topics to markers that any tag colouring will be lost.
The limits of tagging – and of MindManager as a research tool
Apart from the copying difficulties and other issues mentioned earlier, there are a few other issues. One is that the ability to reuse text tags does not apply to icons. While it is possible to copy and paste icon groups using the method described earlier, the copied icons are regarded by MM as being literally the same as the originals. This means for example that if a specific icon is added to a topic in one icon group, the topic will appear and be counted in that group – but it will also be added to and counted in all other icon groups in the Map Index which have a copy of the same icon, thus negating the whole point of the exercise.
There are also some broader issues. I can’t provide exact numbers, but as I noted in Part 1 I have used MM in analysing interviews and surveys with a maximum of 12 respondents. MM seems stable with this number, assuming around 25 to 30 questions and around five to ten tags per question, but it seems to slow down beyond these levels. It is wise to back up frequently as you build the map; I also export it to Word during this process to ensure there is a backup which can be accessed easily if the map becomes unstable.
Even with a map this size I have encountered difficulties which appear to result from the repeated application of different complex filters. It is wise from time to time to clear all filters and resave and close the map (or just close it if you haven’t added or changed anything while the map was filtered) then reopen it to ensure that does not become unstable. I always save a map in an unfiltered state when I have finished with it for the day.
These issues underline the fact that MM has limitations as a research tool. While the techniques I describe demonstrate MM’s versatility and adaptability and have worked well for me, I acknowledge that the program was not designed for this purpose. If you are undertaking studies involving hundreds of respondents, if the results are largely quantitative and/or if they require complex statistical analysis, then there are better – albeit usually more expensive – tools around.
On the other hand, if you are looking for an effective way to undertake qualitative analysis of interviews or survey results involving a relatively small number of subjects then MindManager is well worth a look, especially since the introduction of reusable tags has made it much easier to use for this purpose. Reusable tags are also likely to be helpful for other uses apart from research, for example, the assessment and ranking of organisation policy and project options.

Pingback: MindManager 2017’s new features in action – 3: researching with reusable tags (part 1) | Sociamind
This is very helpful, Alex. I have tried to use tags and filters on larger data sets. It is clumsy but it does work. For more complex statistical analysts using Pearson product moment correlation coefficients, it is better to use Excel for data analysis. T-test, chi square and other tests with large data sets I use Excel and import the results into MM.
LikeLiked by 1 person
Thanks for your comment – and I’m glad there is at least one other person who has thought of using MindManager in this way!
I suspected it was possible to use data set sizes larger than the arbitrary limits I laid out but I did run into some problems particularly when using tags containing a lot of text. I suspect I was having some memory issues as well, but in any case as you point out MM is a bit of a clumsy tool with large data sets; for these, and for more complex statistical analysis, you are much better off using either specialised tools or Excel in the way you suggest.
There are also tools like NVivo for qualitative analysis (or mixed qualitative and quantitative analysis) of large data sets but these are very expensive and in my experience can be unnecessarily complex to use with small data sets. This is the area where I think MindManager can be really useful.
LikeLike